提及的工具與平台
Logos are loaded from a lightweight icon CDN. If any are blocked by your network, the text labels will still display.
 OpenAI
OpenAI
 Anthropic
Anthropic
 Adobe
Adobe
 Microsoft
Microsoft
 ElevenLabs
ElevenLabs
 Google
Google
根據提供的課程資料彙整之教材章節。 Where “Editorial additions” appear, they are clearly labeled.
Logos are loaded from a lightweight icon CDN. If any are blocked by your network, the text labels will still display.
OpenAI
Anthropic
Adobe
Microsoft
ElevenLabs
Google
模組目標 (節錄自課程指南):
關鍵術語 (來自本模組內容):
ELIZA;規則式聊天機器人;關鍵字檢測;自然語言處理 (NLP);機器學習 (ML); 對話代理;Transformer;大型語言模型 (LLM);生成式 AI;推理模型;思維鏈 (Chain-of-thought) 提示; 幻覺 (Hallucination);Tokens;延遲 (Latency);上下文長度 (Context length);ASR;TTS;NLU;語音生物識別;GAN;擴散模型 (Diffusion model);自注意力機制 (Self-attention); 多模態模型 (Multimodal models);微調 (Fine-tuning);DreamBooth;LoRA;APIs;合規性 (GDPR/CCPA/HIPAA/LGPD)。
本模組專為需要「工作流暢度」的領導者編寫——具備足夠的深度來做出負責任的策略決策、提出更好的問題,並在不成為專家的情況下評估權衡。
and links those capabilities to organizational performance and digital transformation. The later sections unpack how we arrived here (chatbots), what makes AI expensive (cost drivers), and how new modalities (audio and images) reshape workflows.
The Course Guide lists “生成式 AI 基礎” as Section 1 of Module 1. The provided Module 1 text begins with chatbot evolution and then expands into cost, multimedia, and advanced tools. This short orientation connects the given content to the official outline.
自 MIT 教授 Joseph Weizenbaum 於 1966 年開發出世界上第一個聊天機器人 ELIZA 以來,聊天機器人的能力已有了顯著演進。 早期的系統是基於規則的:它們檢測關鍵字並返回預先編寫好的回應。這些系統缺乏 NLP 能力,且在範圍和輸出方面都受到限制 (Murphy, 2023)。
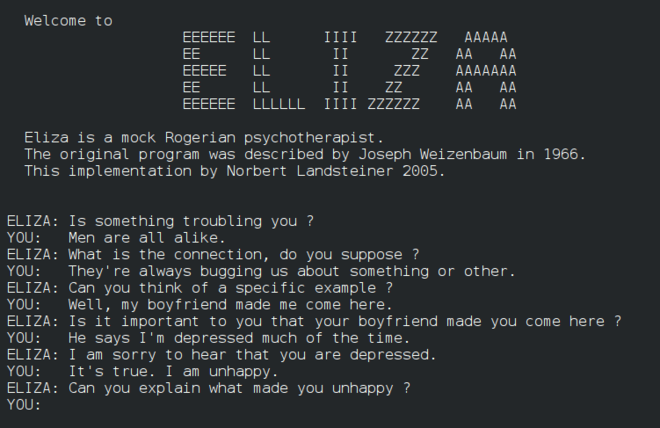
在 2010 年代早期,機器學習 (ML) 的進步催生了新一代的聊天機器人——對話式代理 (conversational agents)—— 它們能更好地理解自然語言,並能完成更複雜的任務 (Murphy, 2023)。範例包括 IBM Watson、Siri 和 Alexa。 2010 年代晚期的發展——基於 Transformer 的神經網路和大型語言模型 (LLMs)——為生成式 AI 聊天機器人鋪平了道路,使其能夠處理更大的查詢量,並提供更個人化、聽起來更自然的回應 (Marr, 2024)。

推理模型 (例如 OpenAI 的 o3 和 o4 模型) 代表了一個較新的里程碑。這些模型經過訓練,可以花更多時間處理查詢,「深入思考」問題後再做出回應,就像人類分析師一樣 (Williams, 2025)。 它們在需要複雜推理的領域 (如科學、程式編碼和數學) 表現出顯著的進步 (Paul & Tong, 2024)。
思維鏈提示旨在提高 LLMs 執行複雜推理的能力。它涉及產生中間自然語言推理步驟,從而得出最終答案,模擬類似人類的思考過程。
範例 (來自模組內容):對於「市場 A 與市場 B」的比較,啟用思維鏈的模型會分別分析各項因素——市場規模、競爭、監管環境——然後再建議方向。
模組內容指出,幻覺仍然是 LLMs 固有風險:模型可能會產生並非基於訓練數據或已知模式的輸出,從而產生虛假或不準確的說法。模組還引用了 OpenAI 的一項研究,指出 o4-mini 在某些指標上的幻覺比早期的 ChatGPT 模型更多。
與主要對提示做出反應的傳統聊天機器人不同,代理式 AI 可以自主且主動地採取行動,適應上下文,並在人為干預最小的情況下於複雜環境中執行目標 (Coshow et al., 2025)。 根據 MIT 的 Abel Sanchez 博士的說法,AI 代理本質上是一個可能涉及人類的工作流程。
說明性使用案例 (來自模組內容):
模組中主張,面向客戶的聊天機器人現在能處理更多查詢,且具備更高的準確性和細微差別,並能根據客戶數據和過往互動提供日益個人化的回應 (Marr, 2024)。它還建議 AI 客戶體驗代理可讓組織在提升參與度的同時,將大部分的客戶互動自動化 (Coshow et al., 2025)。
2024 年,Klarna 採用了由 OpenAI 提供技術支持的 AI 客戶服務助手。據報導,該聊天機器人在首月處理的工作量相當於 700 名全職代理。重複查詢減少了 25%,平均服務時間從人類代理的 11 分鐘降至 2 分鐘。
Octopus Energy 將 ChatGPT 整合到其客戶服務頻道並指定其負責處理查詢。據該公司稱,該系統能處理 250 人的工作量,且獲得的平均客戶滿意度評分高於人類代理。
隨著組織大規模部署 AI,成本和效能成為策略限制。選擇最強大的模型在經濟上可能難以持續,而僅優先考慮低成本則可能限制系統效用。本節解釋了成本的驅動因素,以及如何在實際部署中思考權衡。
高級麵包車適合送孩子上學,但如果你必須送全鎮的每個孩子上學,那就太荒謬了。在大規模情況下,你會選擇巴士、自行車隊或步行小組。同樣地,「最佳」AI 並不總是最強大的模型——而是與限制下的任務最契合的模型。
模組將 Tokens 視為 LLM 使用的主要成本驅動因素。Tokens 是文字單位 (通常約 3–4 個字元)。 輸入和輸出均以 Tokens 衡量並據此定價 (OpenAI, 2023,如模組內容所述)。
模組提供了一個互動範例,其中有 500 個輸入 Tokens 和 1,000 個輸出 Tokens。 以輸入每 1k $0.03 且輸出每 1k $0.06 的費率計算。 確切成本為:(0.5 × $0.03) + (1.0 × $0.06) = $0.015 + $0.06 = 每次互動 $0.075。 這僅修正了算術;策略上的重點 (大規模下的成本複合效益) 保持不變。

模組將部署框架描述為跨以下各項的權衡:
音訊與語言互動聽起來可能很簡單,但它們需要複雜的技術架構。本節區分核心組件 (ASR, TTS, NLU, 語音生物識別)、各行各業常見的組合,以及營運成本動向 (如即時限制與自定義需求)。
| 技術 | 定義 | 常用用途 |
|---|---|---|
| ASR (自動語音辨識) | 將口語轉化為文字 | 轉錄、字幕、指令處理 |
| TTS (文字轉語音) | 將文字轉化為聽起來自然的語音 | 語音助理、旁白、新聞閱讀器 |
| NLU (自然語言理解) | 從語言中判斷意圖與上下文 | 語音客服、對話式代理 |
| 語音生物識別 | 使用獨特的語音特徵進行身分驗證 | 金融科技、醫療保健、高安全性環境 |

| 部門 | 使用案例 | 典型組合 (內容由原文提供) |
|---|---|---|
| 醫療保健 | 聽寫、轉錄、醫病互動 | Whisper + NLP 層 (需符合 HIPAA 合規性) (Paubox, 2025) |
| 零售 | 基於語音的客戶服務亭 | TTS + ASR + 聊天機器人 NLU (PYMNTS, 2024) |
| 教育 | 語言學習、無障礙設施、課程 | TTS (多語言) + 語音評分 (Wood et al., 2018) |
| 金融 | 呼叫中心自動化、情緒分析 | ASR + NLU + 分析評分 (Grace, 2025) |
| 汽車 | 車內語音助理 | 邊緣優化的 ASR + 嵌入式 NLU (EE Times, 2025) |
| 風險 | 範例 | 緩解措施 |
|---|---|---|
| 未經同意的錄音 | 在未通知的情況下錄製使用者語音 | 明確的同意提示與音效指示 |
| 數據保留 | 無限期儲存音訊 | 嚴格的保留政策;允許刪除 |
| 生物識別濫用 | 在未明確同意的情況下使用聲紋 | 要求對語音生物識別進行選擇性加入 (Opt-in) |
| 第三方洩漏 | 將使用者數據不安全地發送到雲端 APIs | 強大的合約 (DPAs) 或內部部署儲存 |
| 跨境傳輸 | 針對歐盟使用者使用美國伺服器 | 遵守國際傳輸協議 (SCCs, DPF) |
本節將焦點從廣泛的技術類別轉向實用的工具集:影像生成、音訊生成、文字生成與影片生成。 本節也解釋了為什麼混合架構 (GANs + 擴散模型 + Transformers) 在實際產品中很常見,以及為什麼代理式 AI 被定位為下一波浪潮。
| 能力 | 使用案例 (內容由原文提供) |
|---|---|
| 影像生成 | 廣告視覺效果;產品模型;概念藝術;演示插圖;資訊圖表 |
| 音訊生成 | 語音代理/IVR;無障礙設施;語言學習;音本/播客敘述 |
| 文字生成 | 郵件草擬;聊天機器人腳本/FAQs;報告與摘要;說明文件與 SOPs;SEO 內容 |
| 影片生成 | 短形式廣告;說明影片;課程影片;概念預告片與分鏡圖 |
模組強調,這些系統越來越多地組合使用:GANs 用於速度/真實感,擴散模型用於多樣性/穩定性, 而 Transformers 用於連貫性與控制——有時是在同一個應用程式中。
| 層級 | 描述 | 範例工具 | 最適合 | 權衡 |
|---|---|---|---|---|
| 現成 APIs | 透過 API 使用託管模型;無需設置;按次付費 | DALL·E 3 (OpenAI API), DreamStudio, Adobe Firefly | 快速原型、行銷影像、一般需求 | 微調空間有限;每次調用需付費;可能的數據鎖定 |
| 開源本地模型 | 在您自己的伺服器/私有雲上安裝模型 | Stable Diffusion (base/XL), HuggingFace Diffusers | 更多控制力、隱私性、品牌一致性 | 設置 + 運算成本;需要內部專業知識 |
| 自定義微調模型 | 在專有風格/數據上訓練模型 | DreamBooth, LoRA, 自定義 SD 分支 (Forks) | 大量品牌特定內容 | 昂貴的訓練 + 持續維護 |
在本模組至今,我們已經探索了 AI、生成式 AI 與代理式 AI (Agentic AI) 的基礎原理——追溯了該領域從早期起源到目前顛覆市場能力的演進。我們也檢視了文字、音訊與視覺技術如何各自為不斷演變的 AI 版圖做出貢獻。
這最後一節將焦點從廣泛的技術類別轉向更實用的觀點:組織可以用來將 AI 功能整合到實際工作流程中並提升績效的特定工具與平台。
模組根據產生的內容類型 (影像、音訊、文字與影片) 對廣泛使用的工具進行分類。這種「工具箱」視圖可幫助領導者將 AI 能力轉化為具體的商業應用。
定義 (自模組框架): 透過文字提示或其他輸入產生影像的 AI 工具,能夠大規模快速建立內容。
使用案例 (內容由原文提供):
使用案例 (內容由原文提供):
使用案例 (內容由原文提供):
使用案例 (內容由原文提供):
生成式 AI 已經在重塑組織建立文字、音訊與視覺內容的方式。下一個前沿是代理式 AI (Agentic AI)——不僅僅是回應命令,而是能主動、做決策並跨工具進行自主協作的系統。在下一個模組中,本課程將探索這種演進如何為大規模自動化、個人化與數位智慧開啟新的可能性。
The following questions are designed to help learners consolidate Module 1 concepts. They are not presented as original course content.
Assignment listed in Course Guide: “Assignment 1: Evaluating the Cost of AI Systems.”
Since only the assignment title is provided, the following is a suggested template to help students apply Section 3’s concepts without inventing course requirements. Adapt as needed to match your facilitator’s instructions.
本清單保留了原 Module 1 內容中出現的參考文獻。如果您提供詳細的書目資料,我們可以再行補充。